
LL(1)-грамматики
Алгоритм 4.6 для построения таблицы предсказывающего анализатора может быть применен к любой КС-грамматике. Однако для некоторых грамматик построенная таблица может иметь неоднозначно определенные входы. Нетрудно доказать, например, что если грамматика леворекурсивна или неоднозначна, таблица будет иметь по крайней мере один неоднозначно определенный вход.
Грамматики, для которых таблица предсказывающего анализатора не имеет неоднозначно определенных входов, называются LL(1)-грамматиками.
Предсказывающий анализатор, построенный для LL(1)-грамматики, называется LL(1)-анализатором. Первая буква L в названии связано с тем, что входная цепочка читается слева направо, вторая L означает, что строится левый вывод входной цепочки, 1 - что на каждом шаге для принятия решения используется один символ непрочитанной части входной цепочки.
Доказано, что алгоритм 4.6 для каждой LL(1)-грамматики G строит таблицу предсказывающего анализатора, распознающего все цепочки из L(G) и только эти цепочки.
Нетрудно доказать также, что если G - LL(1)-грамматика, то L(G) - детерминированный КС-язык.
Справедлив также следующий критерий LL(1)-грамматики. Грамматика G = (N, T, P, S) является LL(1)-грамматикой тогда и только тогда, когда для каждой пары правил A



- FIRST()FIRST(
 ) =;
) =;
- Если e FIRST(
 ), то FIRST()FOLLOW(A) =.
), то FIRST()FOLLOW(A) =.
Язык, для которого существует порождающая его LL(1)-грамматика, называют LL(1)-языком. Доказано,
что проблема определения того, порождает ли грамматика LL-язык, является алгоритмически неразрешимой.
Пример 4.6. Неоднозначная грамматика не является LL(1). Примером может служить следующая грамматика G = ({S, E}, {if, then, else, a, b}, P, S) с правилами:
S  |
|
| E |
|
Эта грамматика является неоднозначной, что иллюстрируется на рис. 4.6.
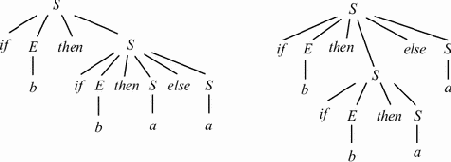
|